Grafana Dashboards optimieren: Präzise Prometheus Metriken statt visueller Täuschung
Monitoring-Tools sind aus der modernen Softwareentwicklung und Cloud-Infrastruktur nicht wegzudenken. Grafana als Visualisierungsplattform und Prometheus als Metrik-Backend bilden dabei eines der am weitesten verbreiteten Gespanne. Es ist erstaunlich einfach, in Grafana ansprechende Graphen zu erstellen, die auf den ersten Blick hervorragend aussehen. Doch oft verzerren diese oberflächlichen Visualisierungen die Realität und führen zu falschen Annahmen über die Systemgesundheit. Wenn kritische Muster im visuellen Rauschen untergehen, wird das Troubleshooting schnell zum Ratespiel. Genau hier setzen wir an, um echte Transparenz zu schaffen.
In diesem Beitrag zeigen wir Ihnen, wie Sie Ihre Grafana Dashboards optimieren, indem Sie typische Fehler bei PromQL-Abfragen vermeiden. Wir demonstrieren praxisnahe Lösungsansätze für präzise Visualisierungen und werfen zudem einen Blick darauf, wie KI-Tools bei der schnellen Einrichtung der zugrundeliegenden Testinfrastruktur helfen können.
Effizientes Infrastruktur-Setup mit KI-Unterstützung
Um Visualisierungskonzepte fundiert zu testen, wird eine verlässliche und realistische Datenbasis benötigt. Das manuelle Aufsetzen einer solchen Umgebung – bestehend aus einer Prometheus-Instanz mit Grafana-Anbindung und repräsentativen Testmetriken – ist oft zeitaufwendig, weshalb der Einsatz von KI-Assistenten hier enorme Effizienzgewinne verspricht.
Testdaten per Skript generieren
Anstatt auf triviale Mock-Daten zu setzen, nutzen wir ein Python-Skript zur Generierung von OpenMetrics. Dieses Skript erzeugt historisch zurückdatierte Metriken, die typische Lastmuster simulieren. Den Link zum GitHub Repo finden Sie in den Referenzen.
Dazu gehören beispielsweise reale Stoßzeiten im Geschäftsalltag oder gezielte Fehler-Spikes. Das Ergebnis ist eine valide, realitätsnahe Testumgebung, die direkt in Prometheus eingespeist wird und als Fundament für tiefgehende Analysen dient.
LLM-Performance im Infrastruktur-Code
Bei der Erstellung der Container-Infrastruktur haben wir verschiedene KI-Assistenzsysteme, darunter Claude und weitere LLMs, miteinander verglichen. Das Bootstrapping grundlegender docker-compose.yml-Dateien und der Basis-Konfigurationen funktionierte hervorragend.
Dennoch stießen die Modelle bei spezifischen PromQL-Feinheiten und komplexeren Architekturfragen an ihre Grenzen. Das Fazit bleibt klar: KI ist ein mächtiges Werkzeug für das Setup, ersetzt aber keinesfalls das tiefe architektonische Verständnis des Engineering-Teams.
Zwei häufige Fehler und wie Sie Ihre Grafana Dashboards optimieren
Selbst mit der besten Infrastruktur im Hintergrund steht und fällt der Nutzen eines Dashboards mit der Qualität seiner Abfragen. Hier lauern zwei spezifische Fallstricke, die Sie unbedingt vermeiden sollten.
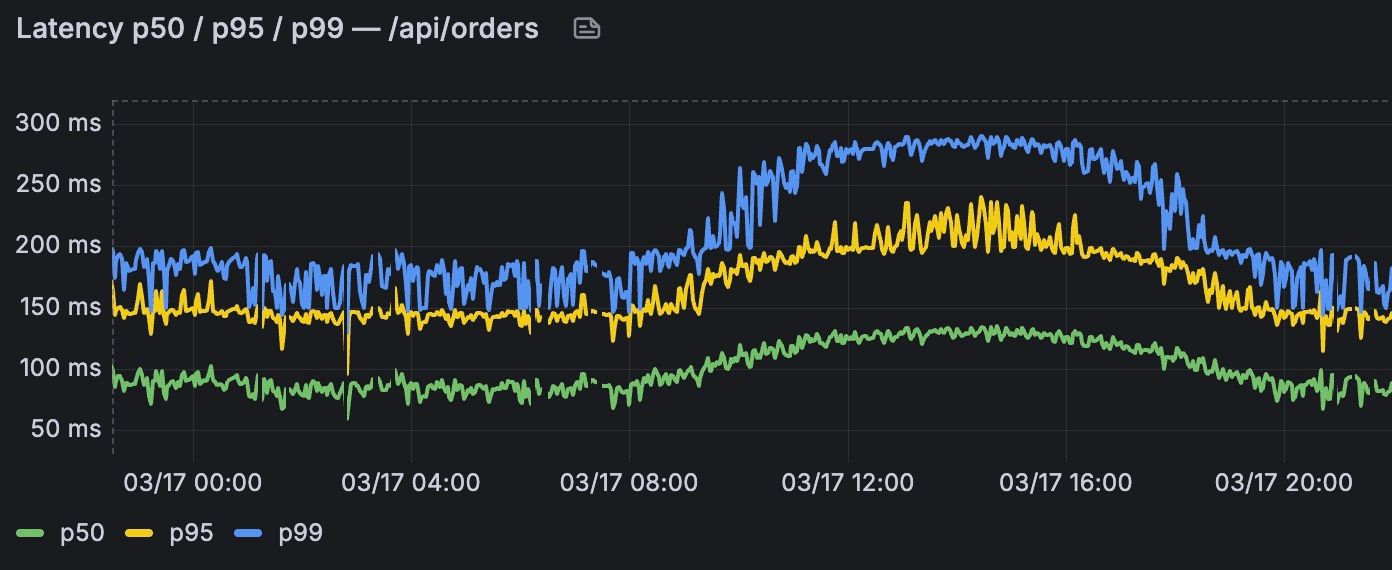
Die Perzentil-Falle erkennen und beheben
Latenzen werden in Prometheus üblicherweise als Histogramme instrumentiert – diese Entscheidung trifft die Applikation, die die Metriken exponiert. Ein Histogramm zählt beobachtete Werte in konfigurierbaren Buckets, wobei jeder Bucket die Anzahl aller Beobachtungen unterhalb einer bestimmten Grenze (dem le-Label) enthält. Die konkreten Latenzwerte der einzelnen Requests gehen dabei verloren; es bleibt nur die Information, wie viele Requests in welchen Bucket gefallen sind.
Die PromQL-Funktion histogram_quantile() berechnet aus diesen Bucket-Zählern Quantile wie das p95 oder p99. Da die tatsächlichen Einzellatenzen nicht mehr bekannt sind, muss die Funktion eine Annahme treffen: Sie nimmt an, dass die Beobachtungen innerhalb eines Buckets gleichmäßig über dessen Spanne verteilt sind, und interpoliert linear zwischen den Bucket-Grenzen.
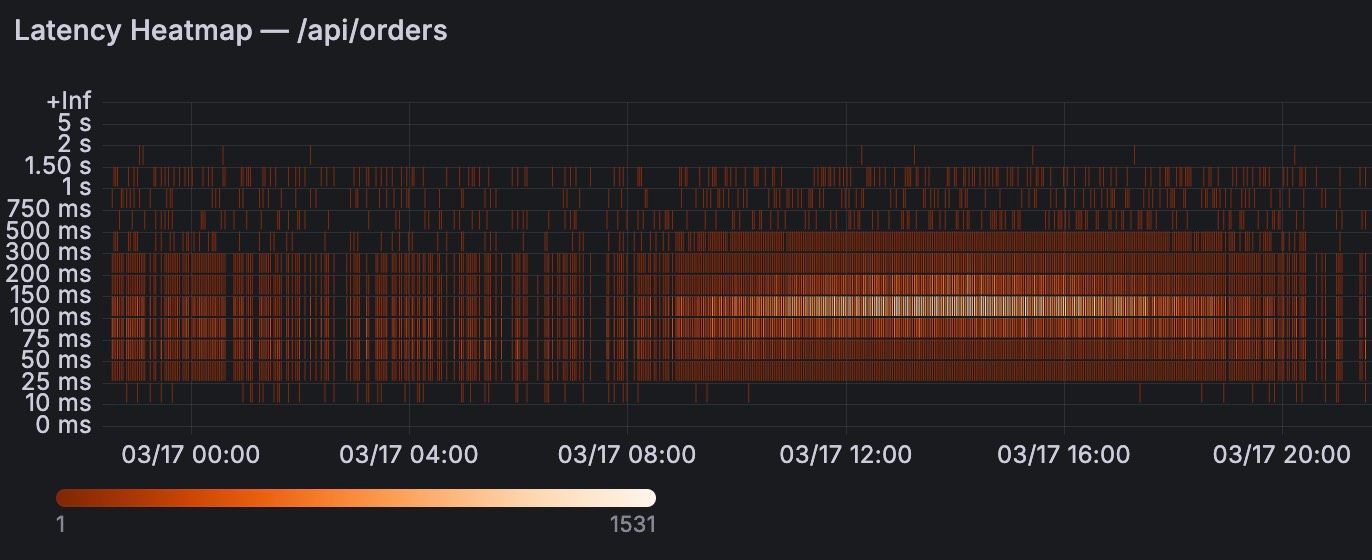
Genau hier liegt die Verzerrung. Ein Beispiel: Der Bucket 1s ≤ x < 5s enthält drei Requests, die in Wirklichkeit alle bei 1 Sekunde lagen. Die Funktion „erfindet" daraus rechnerisch einen Request bei 1 s, einen bei 3 s und einen bei 5 s – Werte, die so nie aufgetreten sind. Je breiter die Buckets und je ungleichmäßiger die reale Verteilung innerhalb eines Buckets, desto stärker ist diese Verzerrung. Das Ergebnis ist ein p99, das systematisch in Richtung der oberen Bucket-Grenzen gezogen wird und nur ungenau die tatsächliche Latenz widerspiegelt.
Die Lösung: Ergänzen Sie Ihre Perzentil-Graphen stets um eine Heatmap der tatsächlichen Metrik-Buckets. Grafanas Heatmap-Panel zeigt die „rohe Wahrheit" des Histograms – wie viele Requests es zu einem Zeitpunkt insgesamt gab, wie sie sich auf die einzelnen Buckets verteilen und welche Buckets im Histogram überhaupt definiert sind. Gerade bei der Untersuchung einer Spitze in der p99 liefert die Heatmap damit genau den Kontext, den der einzelne Perzentil-Wert nicht geben kann.
Zeitbereiche und Interpolation meistern
Dieser Abschnitt behandelt zwei zusammenhängende, aber technisch eigenständige Probleme: die Wahl des richtigen Zeitfensters in PromQL-Abfragen und die visuelle Darstellung der Ergebnisse in Grafana.
Problem 1: Range Vector Selectors und das Query-Intervall. In PromQL arbeiten Funktionen wie rate() oder increase() auf Range Vectors. Ein Range Vector ist – anders als ein Instant Vector, der pro Serie genau einen Datenpunkt liefert – im Kern eine Matrix: Jede Zeile entspricht einer Zeitreihe, jede Spalte einem Zeitpunkt innerhalb eines rückwärtsgerichteten Fensters. Erzeugt wird er durch einen Range Vector Selector, geschrieben als [5m] oder [1h] hinter dem Metriknamen.
Dieses Fenster sollte niemals hardcoded sein. Grafana stellt dafür die eingebaute Variable $__rate_interval bereit, die sich automatisch am aktuellen Query-Intervall orientieren – also am Abstand zwischen den abgefragten Datenpunkten, der wiederum vom gewählten Zeitraum abhängt. Die empfohlene Form lautet somit rate(metric[$__rate_interval]).
In der Praxis stößt das automatische Verhalten jedoch an Grenzen: Bei großen Dashboard-Ranges errechnet Grafana oft Werte, die für eine aussagekräftige Glättung viel zu klein sind; und selbst bei kürzeren Ranges möchte man das Fenster manchmal manuell anpassen, um Rauschen gezielt zu dämpfen oder feinere Strukturen sichtbar zu machen.
![Grafana-Panel „HTTP Request Rate by Path" über zwei Tage mit drei Endpunkt-Kurven (users, orders, search) und sichtbaren Tageszyklen — daneben die Query mit rate(...[$__rate_interval]) und einer „Min Range"-Dashboard-Variable.](/uploads/boxy_Rates_Per_Path_bbfdecda2e.png)
Die Lösung: Führen Sie eine benutzerdefinierte Dashboard-Variable ein – etwa eine Interval-Variable namens „Min Range" mit Werten wie 1m, 5m, 10m, 15m, 30m, 1h, 3h, 6h, 12h, oder 1d. Wichtig ist, diese Variable an der richtigen Stelle zu verwenden: nicht direkt im Range Vector Selector, sondern in der Panel-Einstellung Min step (bzw. Min interval) der Prometheus-Abfrage. Dadurch wird das von Grafana berechnete Query-Intervall nach unten begrenzt, und die eingebauten Variablen $__rate_interval bzw. $__interval im Range Vector Selector passen sich entsprechend an. Die Nutzenden erhalten so die Kontrolle über die Granularität, ohne dass die Abfragen selbst umgeschrieben werden müssen.
Problem 2: Visuelle Interpolation zwischen Messpunkten. Grafanas Time-Series-Panel verbindet Datenpunkte standardmäßig mit geraden Linien (lineare Interpolation). Das erzeugt irreführende diagonale Linien zwischen zwei Messpunkten und suggeriert einen graduellen Übergang, wo in Wahrheit keine Daten vorliegen. Konfigurieren Sie stattdessen die Linien-Interpolation auf „Step before": Der Graph zeigt dann horizontale Stufen und kommuniziert visuell eindeutig, dass zwischen zwei Messpunkten keine neuen Daten erfasst wurden.
Fazit
Um verlässliche operative Entscheidungen zu treffen, müssen Monitoring-Daten die Realität möglichst genau abbilden. Wenn Sie Ihre Grafana Dashboards optimieren, sorgen Heatmaps für den essenziellen Kontext hinter Perzentil-Werten, während saubere Interpolationen und Dashboard-Variablen visuelle Fehlinterpretationen proaktiv verhindern.
Der Einsatz von KI-Tools beschleunigt dabei das initiale Setup der Testinfrastruktur enorm, erfordert jedoch weiterhin menschliche Expertise für den analytischen Feinschliff. Ganz im Sinne unseres Leitgedankens: Do it RIGHT. Nur durch technische Präzision schaffen Sie die nötige Transparenz und das Vertrauen in Ihre Cloud-Infrastruktur.
Referenzen
- •GitHub Repo zu diesem Beitrag (Python Skript, Docker Setup, …)
- •Grafana Time Series Panel (Interpolationsmodi inkl. „Step before")
- •Grafana: Prometheus Template Variables (inkl.
$__rate_interval)
- •Prometheus: Histograms and Summaries (Best Practices, Quantil-Schätzfehler)
- •Prometheus: Querying Basics (Instant vs. Range Vector Selectors)





