
- Published on
Migrating from Mainframe to Kubernetes cluster
- Authors

- Name
- Onur Kasimlar

Intro
In this article we will show how developer teams can avoid unnecessary problems when migrating software from legacy systems into a cloud environment. The dream of every software developer is to start a new project from scratch without any restrictions concerning programming languages and tools which should be used. But it is rarely the case that IT projects have no restrictions concerning the technologies, especially in case of migration projects where teams must deal with legacy code. The effort required for software migrations depends on several factors. The major influences are:
- Difference between the old and the new environment
- Size of the legacy system
- Documentation of the legacy system
- Quality of the legacy system: architecture, code, …
- People with knowledge about the legacy system
- ….
For systems, where it is very likely that the legacy code will be changed during the migration process (e.g., bug fixes, software change request), an iterative migration is preferred over a big-bang migration. An iterative migration also lowers the risk of a failure. Problems with the new environment can be discovered early in the whole migration process, which reduces the costs to fix them enormously.
What is Strangler Fig Pattern
For an iterative migration it is inevitable to follow a precise procedure. A migration pattern introduced by Martin Fowler for iterative migrations is the Strangler Fig Pattern. The Strangler Fig Pattern is used to incrementally transform a monolithic legacy system into a modern microservice architecture.

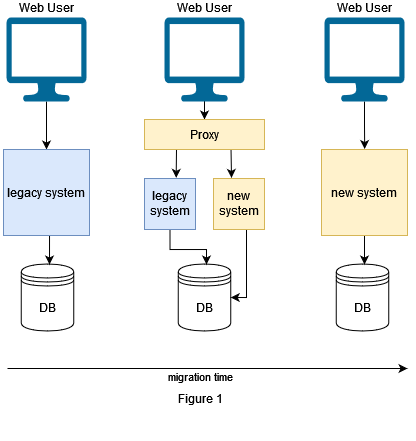
As we can see in Figure 1 the first step is to implement a proxy responsible for routing requests. The proxy decides whether the requests are routed to the old system or to the new one. Once a new component is implemented, we can test the migrated component in parallel against the existing monolithic code. If we have early adopters the proxy can be configured so that these users are routed to the new system, while others still use the old one. After the migration is completed, we can remove the proxy.
This is easier said than done. In the following we show a simplified version of a software migration according to the Strangler Fig Pattern.
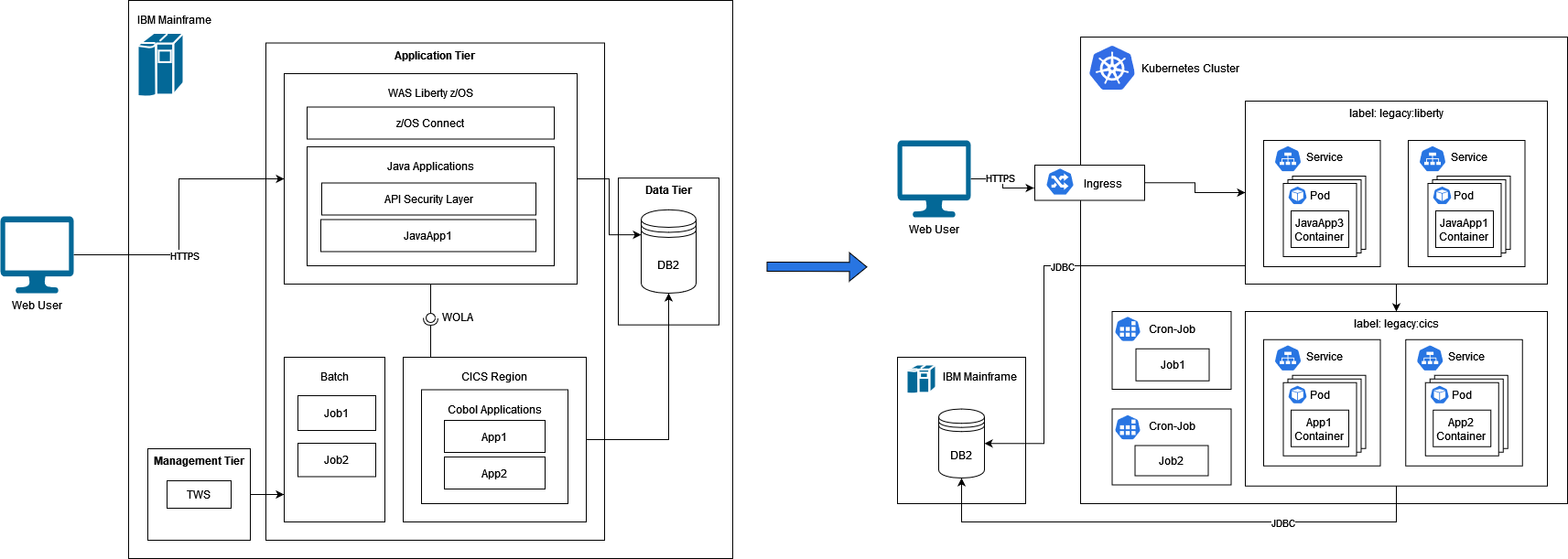
IBM Mainframe to Kubernetes cluster
In Figure 2 we have an infrastructure diagram with applications that should be migrated to a Kubernetes cluster running in the cloud. Applications which are written in Cobol should be reengineered and transformed into the programming language Java. All applications of the legacy system are running on an IBM mainframe (z/OS). We have separated the mainframe into three logical tiers which we are going to describe briefly. Detailed information about the tools running on the IBM mainframe can be found on the internet.

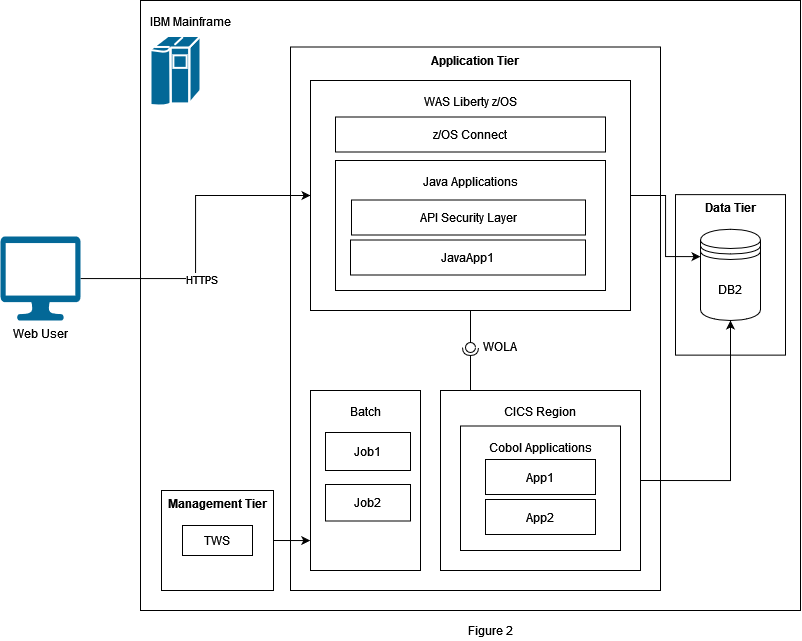
Application tier
In this tier we have all the business applications running on the mainframe. Some are old applications written in Cobol and running in a CICS environment. Newer applications were written in Java and deployed in WAS (WebSphere Application Server) Liberty. With z/OS Connect EE embedded in the WAS Liberty it is possible to create APIs (e.g., REST) to access the IBM mainframe. WOLA1 is an extension to the existing cross-memory exchange mechanism of WAS Liberty. It provides an external interface so z/OS address spaces outside the WAS Liberty server may participate in cross-memory exchanges. In our example WOLA is used for the connection between WAS Liberty and CICS. Besides CICS and WAS Liberty we have batch jobs which are managed by IBM TWS (Tivoli Workload Scheduler)2.
Management tier
TWS, formerly known as OPC, is a workload automation or batch job scheduling engine. It has multiple options to trigger batch jobs. In our example the jobs are called repetitively at pre-specified times. But it is also possible to trigger the jobs manually at any given time from admins by using TWS Dataset Triggering. With TWS Dataset Triggering it is possible to start jobs by adding datasets into the database.
Data tier
As database we use IBM DB2. This database will continue to be used after the migration.
As a first step we must define the order in which the components should be migrated. It is recommended to start with a small component as a proof of concept for the whole migration. Preferably it should cover most of the issues we will face during the migration process. In our small example we decided to migrate the components running in the CICS environment first. This means that we must start with reengineering and transforming the code to Java. Depending on the legacy code and the knowledge in both programming languages the effort may vary strongly. In most cases the legacy code is reengineered first and split from a monolith into smaller components. There are various strategies how this could be achieved, but that would go beyond the scope of this post.

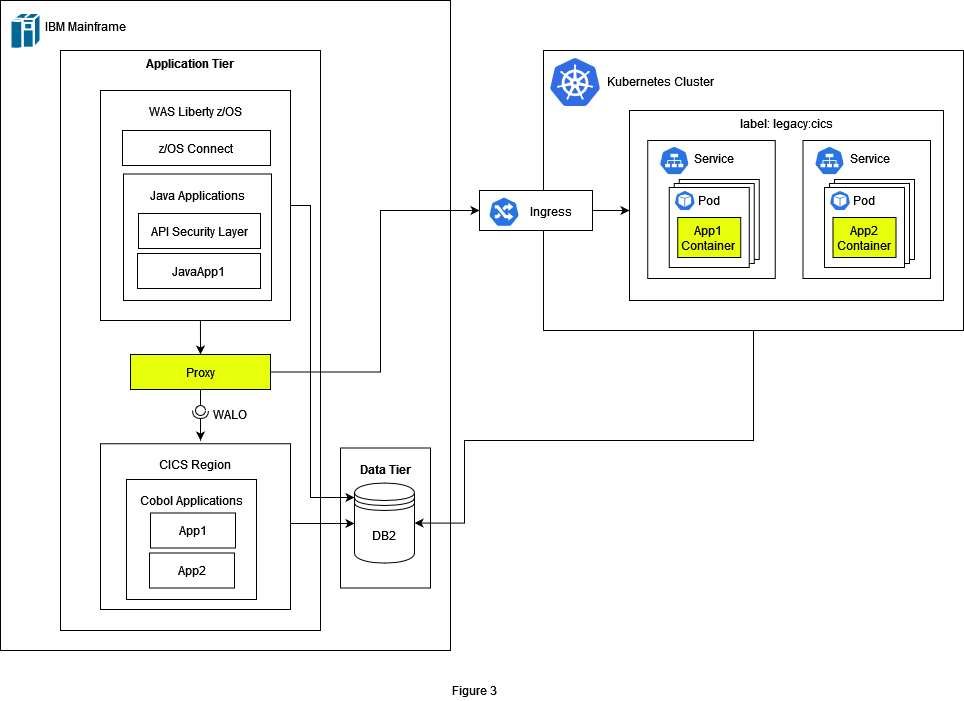
In Figure 3 we see the infrastructure after the migration of the Cobol components. We introduced a proxy server which is responsible for routing the requests to the right system. The requests are either routed to the Kubernetes cluster or to CICS. It is recommended to run the migrated components in parallel with the legacy code and reduce the risk by slowly rolling out the change to a small subset of users. This technique is called canary release and is a widely used approach in software engineering. In Kubernetes we have labelled the components from CICS with the label legacy:cics to keep an overview of the source of the components in the legacy system.

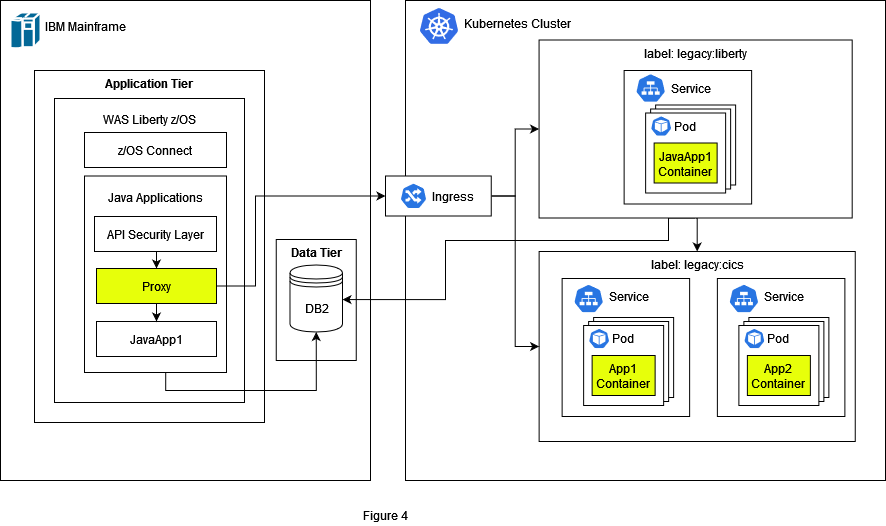
Nevertheless, the Java code must also be adapted. It is often the case that legacy Java code needs to be refactored to perform well in the cloud. For this, frameworks like SpringBoot or Quarkus are widely used. We are going to show in a separate article the advantages of Quarkus and how it works on Kubernetes. We group the component from WAS liberty with the label legacy:liberty.

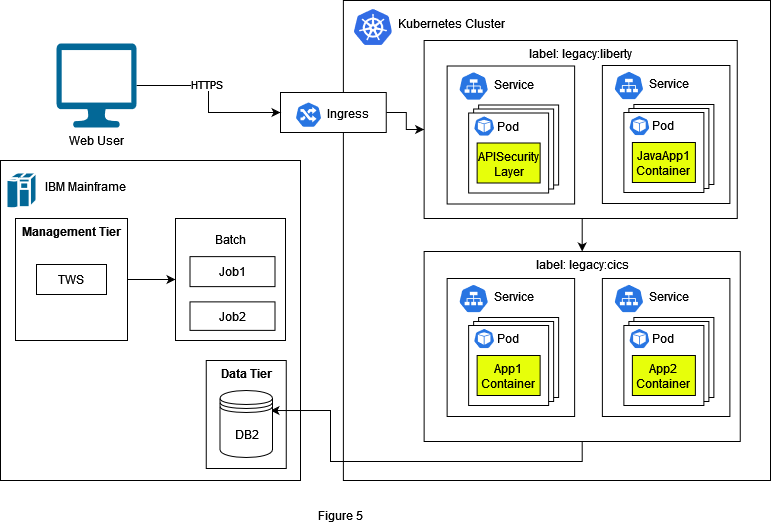
The batch jobs can be migrated as Kubernetes CronJobs. Here we must consider that TWS is a powerful tool and depending on requirements we might need a custom job manager in Kubernetes. But in our simple example the jobs are scheduled repetitively at pre-specified times, so Kubernetes CronJobs are enough to fulfil this requirement. As we have mentioned before in this article TWS also allows triggering of jobs manually by using TWS Dataset Triggering. This requirement will be fulfilled with Change Data Caputre (CDC) technology. We are going to have a deeper look into this topic and different methods of CDC in a separate article.

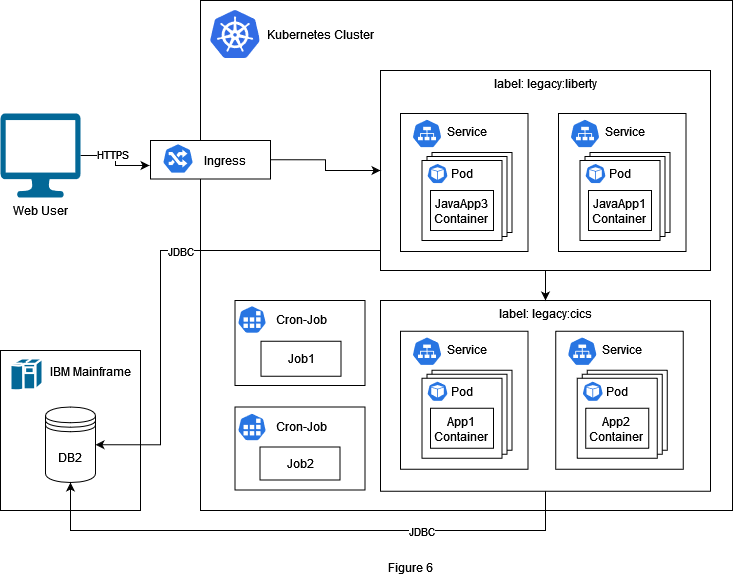
Conclusion
In this article we have shown a simplified version of a software migration with Strangler Fig Pattern. Every migration project, especially between legacy systems and cloud, has its own challenges, but it is very important to have a concrete migration plan. A detailed migration plan will reduce the risks of a failure. Migration patterns, like the Strangler Fig Pattern, are very helpful to create a migration plan, but we must keep in mind that there a lot of other aspects which influence the success of a migration project.